AWS Database Blog
Schedule Amazon RDS stop and start using AWS Lambda
Amazon Relational Database Service (Amazon RDS) makes it easy to set up, operate, and scale a relational database in the cloud. Traditional relational databases require time spent on capacity planning, maintenance, backup, and recovery; a substantial amount of a database administrator’s time is lost to these tasks. Amazon RDS helps DBAs to focus on other important tasks that add value to the organization by automating most routine tasks.
In a typical development environment, dev and test databases are mostly utilized for 8 hours a day and sit idle when not in use. However, the databases are billed for the compute and storage costs during this idle time. To reduce the overall cost, Amazon RDS allows instances to be stopped temporarily. While the instance is stopped, you’re charged for storage and backups, but not for the DB instance hours. Please note that a stopped instance will automatically be started after 7 days.
This post presents a solution using AWS Lambda and Amazon EventBridge that allows you to schedule a Lambda function to stop and start the idle databases with specific tags to save on compute costs. The second post presents a solution that accomplishes stop and start of the idle Amazon RDS databases using AWS Systems Manager.
Solution overview
AWS Lambda is a compute service that lets you run code without managing any servers. You don’t have to worry about provisioning servers, configuring the operating systems, installing applications, and so on.
Amazon EventBridge uses simple rules in which you can create events and assign specific actions in response to them.
Amazon RDS provides different instance types optimized to fit different relational database use cases. The compute costs for most of these instances are billed on an hourly basis. Database instances provisioned in dev or test environments that remain idle for extended periods of time (due to the intermittent nature of the tasks performed on them) can be automatically stopped on a nightly basis and started before business hours by using Lambda functions and EventBridge rules. In this proposed solution, we use a Lambda function to store the code that stops or starts all the RDS instances that have a tag DEV-TEST, and use EventBridge Events rules to trigger the Lambda functions.
The following diagram illustrates our solution architecture.

To implement the solution, you complete the following high-level steps:
- Provision the following resources:
- Tags for your RDS instances.
- An AWS Identity and Access Management (IAM) policy and role for your Lambda.
- Two Lambda functions to stop and start your databases.
- Create Amazon EventBridge rules to trigger the Lambda functions as needed.
Prerequisites
To follow the steps in this post, you need the following:
- An AWS account with administrator access to Amazon RDS.
- An RDS instance that you want to shut down and start on a schedule.
Provision the resources
The following steps explain how to create tags, an IAM policy and role for Lambda, and the Lambda functions that we schedule to stop or start the databases.
Create tags
You can assign tags while creating a DB instance or by modifying the instance after it’s created. The following steps walk you through assigning tags for a scheduled stop and start:
- On the Amazon RDS console, choose a database and the instance within that database that you want to add tags to.
- On the Tags tab underneath the instance details, choose Add tags.

- For Tag key, enter
DEV-TEST. - For Value, enter
Auto-Shutdown. - Choose Add.

You can now see the added tags on the Tags tab.

Create an IAM policy and role for Lambda
We now create an IAM policy and role for Lambda to start and stop the instances.
- On the IAM console, under Access management in the navigation pane, choose Policies.
- Choose Create policy.
- On the JSON tab, enter the following policy code:
- Choose Review policy.
- For Name, enter
rdsstopstart.
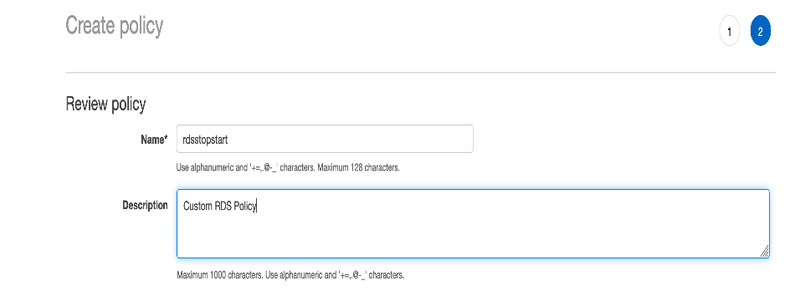
- Choose Create policy.
We now create the IAM role. - In the navigation pane, choose Roles.
- Choose Create role.

- For Select type of trusted entity, choose AWS service.
- For Common use cases, choose Lambda.
- Choose Next: Permissions.
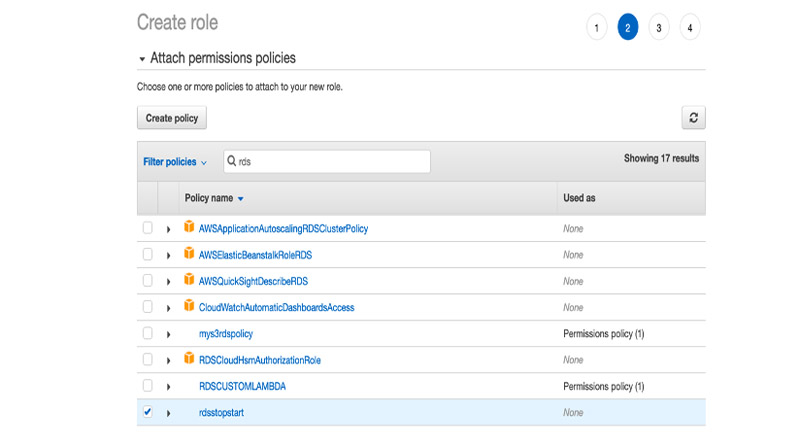
- Search for and select the policy you created (
rdsstopstart).
- Choose Next: Tags.
- In the Tags section, provide your key and value (Optional)
- Choose Review.
- For Role name, enter
rdsLambda. - Review the attached policies and choose Create role.
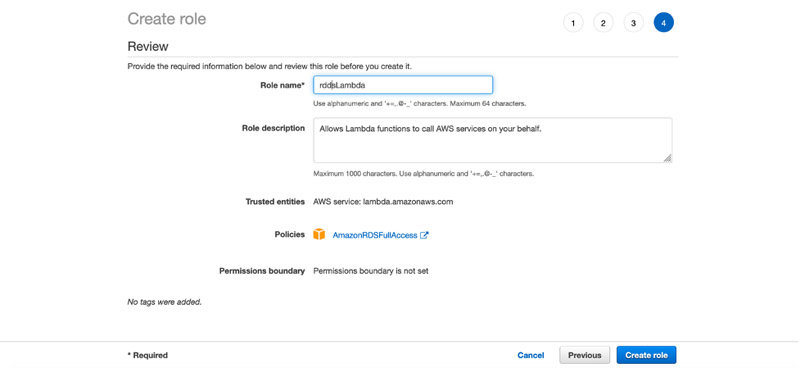
You can now attach this role while creating your Lambda functions.
Create your Lambda function to stop the database
For this post, we create two Lambda functions that can be called to stop and start the databases. We first walk you through creating the stop function.
- On the Lambda console, choose Functions in the navigation pane.
- Choose Create function.

- For Function name, enter
stoprds. - For Runtime, choose Python 3.7.
- For Execution role, select Use an existing role.
- For Existing role, choose the role you created (
rdsLambda).

- Choose Create function.
- On the function details page, navigate to the function code.
- Delete the sample code and enter the following.
- Choose Save.
The above lambda function needs 3 parameters (REGION, KEY, VALUE) to be passed as environment variables. REGION is where the RDS instances are currently running, KEY and VALUE are the Tags that we have attached for the instances that require auto shutdown in the previous steps. Please note the values that we attached to the RDS instances should match exactly to the environment variables. Please follow the below steps to enter these. - Navigate to the ‘Configuration’ tab and choose ‘Environment Variables’. Click on the EDIT and add the Environment Variables as shown below.
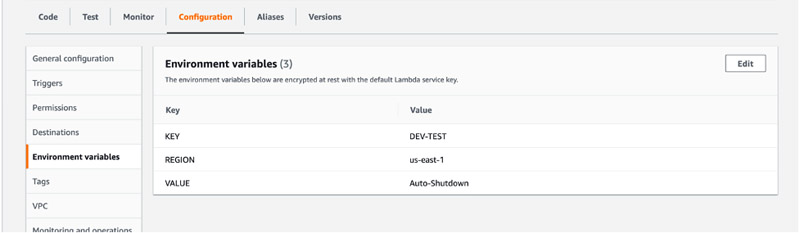
- Choose Test to test the function.

The Configure test event page opens. - For Event name, enter
stop. - Choose Create.

- Choose Test again to test the function.
The test stops the database with the tags specified in the function. You can see on the function detail page that the function was successful.

Create your Lambda function to start the database
Repeat the same steps to create the start function, called rdsstart. Use the following code:
The above lambda function needs 3 parameters (REGION, KEY, VALUE) to be passed as environment variables. REGION is where the RDS instances are currently running, KEY and VALUE are the Tags that we have attached for the instances that require auto shutdown in the previous steps. Please note the values that we attached to the RDS instances should match exactly to the environment variables. Please follow the below steps to enter these.
Navigate to the ‘Configuration’ tab and choose ‘Environment Variables’. Click on the EDIT and add the Environment Variables as shown below.

Testing the function should provide the following output.

After you create and test both functions, we can create EventBridge rules to trigger these functions as needed.
Create your Amazon EventBridge Rule
Amazon EventBridge rules trigger the functions we created to either stop or start the tagged database. For this post, we configure them to trigger on a schedule.
- On the EventBridge console, under Events in the navigation pane, choose Rules. Under the Create rule section, define a name for the rule as shown below.

- Under the Define Pattern section, select Schedule and click on Cron expression and Enter
0 23 ? * MON-FRI *(This cron expression stops databases Monday to Friday at 11:00 PM GMT) as shown below.

- In the Select event bus section, choose AWS default event bus and Enable the rule on the selected event bus (by default they will be enabled).

- In the Select Targets section, choose Lambda Function In the first drop-down box.
- For Function, choose the stop function you created (
stoprds).

- Review the details entered and select Create at the bottom of the page to create the Rule.
The EventBridge rule now triggers thestoprdsLambda function at the scheduled time. - Repeat these steps to create a rule to trigger the
rdsstartLambda function at the preferred scheduled time.
Summary
This post demonstrated how to schedule a Lambda function to stop and start RDS databases in dev and test environments when they’re not in use. The benefits of automating the startup and shutdown of RDS DB instances using Lambda allows organizations to further reduce compute costs and simplify the administration of database environments that don’t need to be running continuously.
We encourage you to try this solution and take advantage of all the benefits of using AWS Lambda and Amazon Relational Database Service. You can also accomplish Amazon RDS Stop and Start using AWS Systems Manager, check out the blog post “Schedule Amazon RDS stop and start using AWS Systems Manager”
Please feel free to reach out with questions or requests in the comments.
About the authors
 Yesh Tanamala is a Database Migration Consultant with AWS Professional Services. He works as a database migration specialist to help internal and external Amazon customers move their on-premises database environment to AWS data stores.
Yesh Tanamala is a Database Migration Consultant with AWS Professional Services. He works as a database migration specialist to help internal and external Amazon customers move their on-premises database environment to AWS data stores.
 Sharath Lingareddy is a Database Architect with the Professional Services team at Amazon Web Services. He has provided solutions using relational databases including Amazon RDS. His focus area is homogeneous and heterogeneous migrations of on-premise databases to Amazon RDS and Aurora PostgreSQL.
Sharath Lingareddy is a Database Architect with the Professional Services team at Amazon Web Services. He has provided solutions using relational databases including Amazon RDS. His focus area is homogeneous and heterogeneous migrations of on-premise databases to Amazon RDS and Aurora PostgreSQL.
 Varun Mahajan is a Solutions Architect at Amazon Web Services. He works with enterprise customers helping them align their business goals with the art of the possible using cloud-based technologies. He enjoys working with data and solving problems using the AWS database and analytics portfolio.
Varun Mahajan is a Solutions Architect at Amazon Web Services. He works with enterprise customers helping them align their business goals with the art of the possible using cloud-based technologies. He enjoys working with data and solving problems using the AWS database and analytics portfolio.