
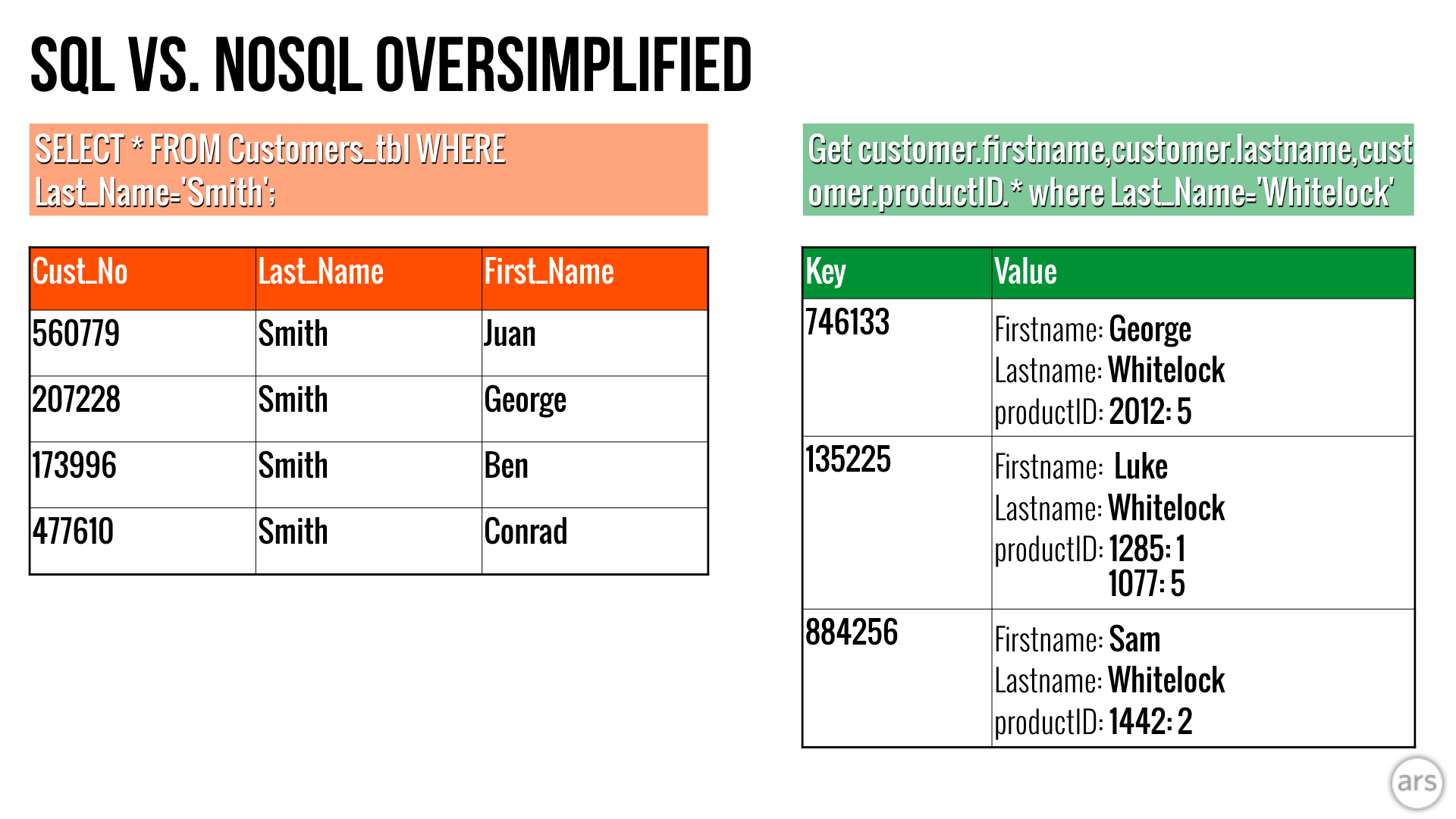
Poke around the infrastructure of any startup website or mobile app these days, and you're bound to find something other than a relational database doing much of the heavy lifting. Take, for example, the Boston-based startup Wanderu. This bus- and train-focused travel deal site launched about three years ago. And fed by a Web-generated glut of unstructured data (bus schedules on PDFs, anyone?), Wanderu is powered by MongoDB, a "NoSQL" database—not by Structured Query Language (SQL) calls against traditional tables and rows.
But why is that? Is the equation really as simple as "Web-focused business = choose NoSQL?" Why do companies like Wanderu choose a NoSQL database? (In this case, it was MongoDB.) Under what circumstances would a SQL database have been a better choice?
Today, the database landscape continues to become increasingly complicated. The usual SQL suspects—SQL Server-Oracle-DB2-Postgres, et al.—aren't handling this new world on their own, and some say they can't. But the division between SQL and NoSQL is increasingly fuzzy, especially as database developers integrate the technologies together and add bits of one to the other.
The genesis of NoSQL
In the beginning—about 12 years ago—there was structured data, and it was good. Usually consisting of things like numbers, dates, and groups of words and numbers called strings, structured data could be displayed in titled columns and rows that were easy to order. Financial companies loved it: you could put customers' names and account balances into rows with titled columns, and you could put the data into tables and do other things with it, like join tables and run queries in a language, SQL, that was pretty close to English.
But that data was live, stored in operational systems like Enterprise Resource Planning (ERP) setups. People wanted to squeeze intelligence out of it, to answer questions like how sales were going or how various regions were doing. The IT department was loathe to do it, though, wary of letting people hit on operational systems. So data was divided into operational and analytical, and thus data warehouses were born. As the questions analysts wanted to ask data became more complex and the amount of data stored became increasingly vast, the databases that held all this began to look less and less like SQL.
SQL-based relational servers are built to handle the demands of financial transactions, designed around the tenets of ACID: Atomicity, Consistency, Isolation, and Durability. These characteristics ensure that only one change can be written to a data field at a time, so there are no conflicting transactions made. If you withdraw $50 from an ATM in Boston, and your spouse simultaneously withdraws $100 from the same account at an ATM in Tokyo, the balance change has to reflect both—not to mention, it must cancel out one of them if the account is overdrawn. Consistency means that no matter which database server you ask, you'll get the same value no matter who's asking or when.
ACID, though, doesn't matter much when you're just reading data for analysis. And the database locks that SQL databases use to protect database consistency in transactions can get in the way. The Internet ushered in what VoltDB Director of Product Marketing Dennis Duckworth calls "Web-scale attacks" on databases: as in, up to hundreds or even millions of people wanting access to the same data sources at the same time. Think of the "not available" messages you get when you try to access a Web service or site. The database is simply staggering under demand. Too many people trying to change data at the same time gave rise to locks as the databases struggled to maintain consistency.
How do you scale an Internet business to handle that? It used to be that you'd buy a bigger server—an HP Superdome, say, or a huge mainframe that could scale up. But that got expensive fast. Businesses turned to buying cheaper, commodity boxes to scale out instead of up, distributing the database out over hundreds or even thousands of servers.
But outside of financial transactions, you don't always need the most up-to-the-second abilities to write data. "Pretty close" can be good enough, such as when the database is just overwriting old data and it's OK to get the results a little wrong for a few minutes. Think of Google's indexing. Its search engine indexes the entire visible Internet every day. It can't write the data while people are simultaneously Googling the same search terms, so it doesn't give us the most up-to-date result when we search. It gives us the last, best answer it can.
That setup is a little sloppy, and it wouldn't work for financial transactions. But that ability is just fine for developers who need drop-dead-fast results, not pinpoint perfect.
NoSQL databases are often associated with "big data" tasks, handling large volumes of data in various forms:
- Columnar databases, for dealing with massive collections of simple structured data, such as log files. Google, for its part, has Bigtable: a distributed, column-oriented data store to handle structured data associated with the company's Internet search and Web services operations, including Web indexing, MapReduce, Google Maps, Google Book Search, "My Search History," Google Earth, Blogger.com, Google Code hosting, YouTube, and Gmail.
- Key-value and other unstructured databases such as MongoDB, which use rules defined by programmers to comb through large amounts of unstructured data, including documents and websites.
- High-speed databases for processing large streams of data with extremely low latency. Those diverging tasks have driven the evolution of some very different technologies that often get lumped together as NoSQL, and some that are labeled as "NewSQL." These provide some of the things that SQL-based relational databases do but are tuned heavily for handling the demands of big data. VoltDB falls into this category: it's a high-speed SQL database. Couchbase is another high-speed, more general-purpose, NoSQL database.

Hadoop
Hadoop isn't even really considered a database, but when you look at databases, you'll no doubt come across it. It was designed as a cheap way to store data and process it someday, in some way. Currently, it's huge. Hadoop is everywhere online: Facebook, eBay, Etsy, Yelp, Twitter, Salesforce. It's in the physical world, too, as companies in entertainment, energy management, and satellite imagery look to analyze the unique types of data they're collecting. Eye-popping forecasts predict that the Hadoop market is on track to hit $84.6 billion by 2021.
Hadoop is enabled by a technology Google created called MapReduce, a way to process and generate large data sets with a parallel, distributed algorithm on a cluster. Google wrote a few papers on it, and then it got picked up by Yahoo programmers who brought it into the open source Apache environment. MapReduce evolved into what Yahoo hoped would be an answer to its search engine woes: an open source platform called Hadoop that collects data from sources such as social media, customers, and financials, storing it in a data warehouse to undergo the MapReduce process. It has made it easier and cheaper than ever to analyze the data being churned out by the Internet. Fun database fact—Hadoop was named after a toy elephant.
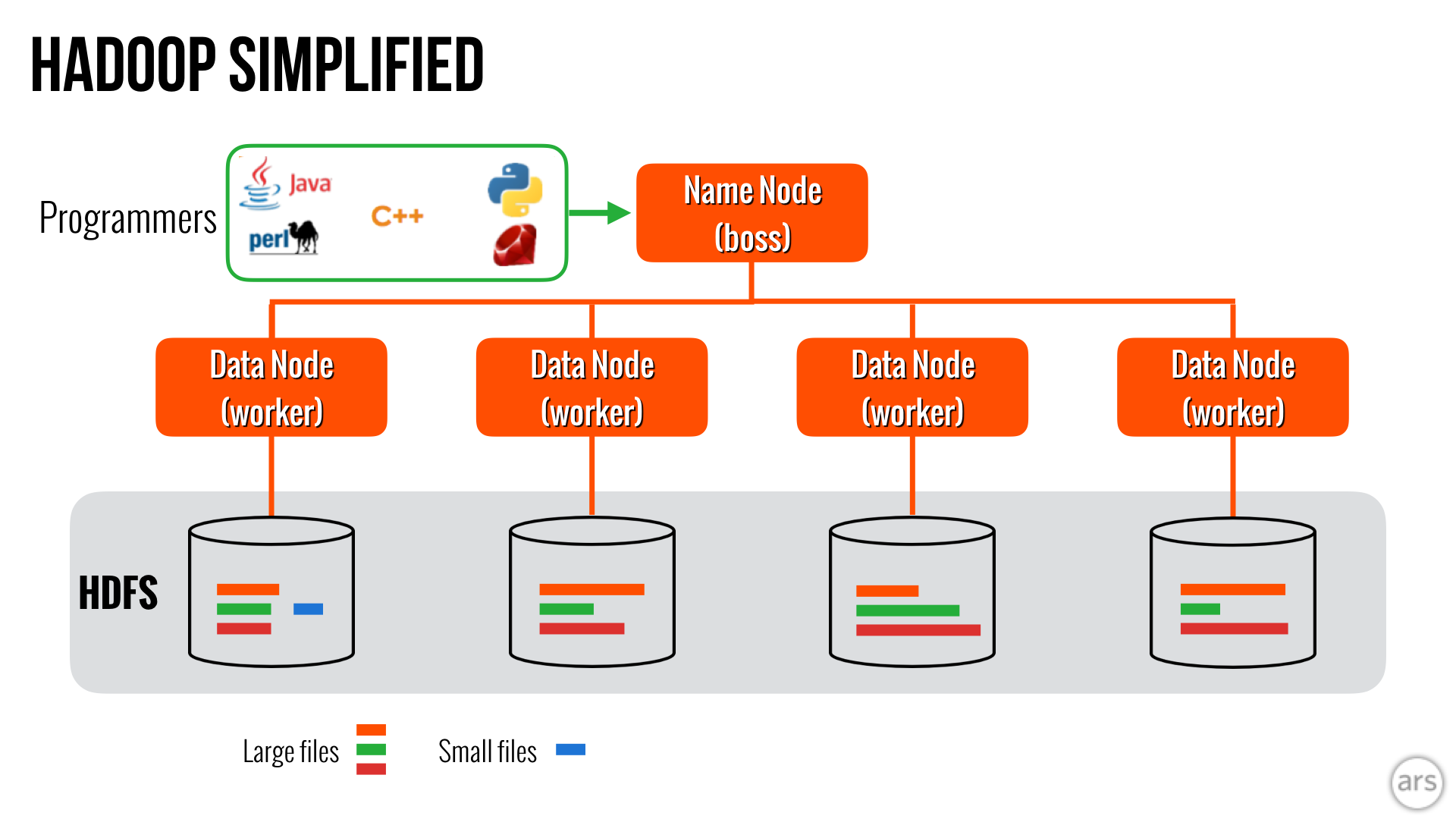
But Hadoop isn't for everyone. It's the opposite of plug and play. Forget the user-friendly language of SQL; Hadoop needs trained, talented experts who know how to manage big data. Developers have released software solutions like Cassandra, HBase, Hive, Pig, and ZooKeeper to interact with this SQL-unfriendly stuffed elephant, but Hadoop also needs a front end. The list of what it needs goes on, as you can see on a chart put together by Gigaom three years ago that displays as many layers as a pallet of Sacher Tortes.
Patrick Lie, a big-data engineer, encountered Hadoop when he was an engineering manager at TokBox, a WebRTC platform for embedding live video, voice, and messaging into websites and mobile apps. The company used Hadoop to mine data in server logs and client communications. That included things like video bit rate. It was a typical use case for Hadoop, he said. The work involved "a lot of data ingestion."
"It was a couple million rows [of data] a day," Lie told Ars. "[We'd] pull it in, process it, and make it available for analysts... [We didn't] care how fast it was processed. It's moved in one direction. You put it through the pipeline, and you put it out in a cleaner, more usable fashion. It's not used again by customers unless it's manipulated heavily."
Here's a typical piece of analysis his team would get out of Hadoop: TokBox had videoconferencing technology happening inside of a browser. Different browsers would give different video performance. Lie's team would get information such as what type of browser was in use, what the video bit rates were, and where the users were located, perhaps based on IP address. Aggregating that data across many users, TokBox could come away with a realization such as, "Hey, Chrome works better than Internet Explorer in Sweden."
It's theoretically possible to do something like that with a SQL database, Lie said, but in practical terms, "you'd be spending so much for a traditional SQL database, or it would take forever to execute. Before Hadoop, somebody would write custom software to do this kind of processing." It's not so much a black and white, SQL vs. NoSQL situation, of course: TokBox still kept SQL databases around. That's where his team fed portions of Hadoop output for analysts to query more easily.
There are some places where you don't want to use Hadoop, at least on its own—anywhere you need real-time data "in any way," Lie said. If you're looking for real-time work, there are solutions that "sort of work on top of Hadoop," but on its own, Hadoop isn't meant for it according to the engineer.
Another potential problem can arise from writing inefficient queries or trying to do jobs without a basic understanding of how Hadoop works. One mistake that's easy to make, Lie said, is to choose the wrong key to reduce on in key-value pairs. If you choose the wrong key in the map phase, the worst possible case is that the key is a random number between, say, 1 and 1 million. That would create 1 million keys. "It's easy to create inefficient jobs," Lie said. "It can take an hour, or it can take a day. It's easy to make those mistakes."
Scott Gnau, CTO at Hadoop distributor Hortonworks, says Hadoop use cases cut across many industries, all of which are gathering Web data. The list includes retailers, financial services (and yes, Hadoop takes in SQL aggregates, "believe it or not," he said), Internet of Things data from resources such as connected cars or healthcare. Think of all the data, both unstructured and structured, that's created when you visit your doctor. Who's the patient? Who's the doctor? What was the prognosis? X-rays, CAT scans, clinical trials, tests, drug interaction matrices can all be images, all unstructured data. Health insurance payers, providers, and manufacturers and many more are taking advantage of Hadoop to handle all that data, which was once buried in silos in an all-SQL world.
"For 30 years in the IT industry, we've had traditional development models," Gnau said. "We grab users, put them in a room, get their requirements, build out the design, look for data to find structures and reporting, implement and hand it back to users. It was a traditional waterfall approach. Even agile development starts with requirements and winds up with results.
"In Hadoop, you need to challenge that and turn it around. Data is not structured. Users may not know what the requirements are. It's an inverse process—you land the data, find data scientists to find relationships that are interesting and appealing, and turn that into requirements that yield a system. It's the opposite approach to a traditional process."
reader comments
153