The Missing Link to Disrupt the Database Industry
After a long break from blogging, here I am again. Time flies when you’re having fun and the experience at OrientDB has been fantastic so far.
In the last few months, I’ve spoken with Fortune 500 customers, met exceptional and talented investors and realized first-hand (again) the amount of disruption that’s happening in the database industry. Customers have inspired me to think out of the box and see an even larger picture where an operational data store could drastically simplify the architecture and where Open Source plays a fundamental role in reducing costs and improving security.
People have been asking me “What’s the advantage of native multi-model databases?” To help answer that question, we developed our own OrientDB Magic Quadrant (Note: Gartner is not affiliated).
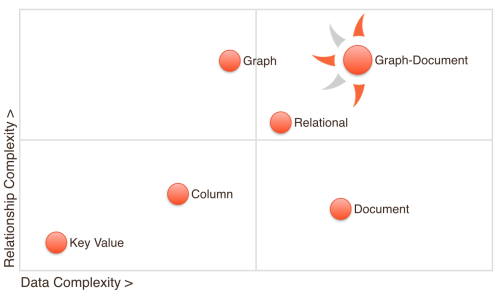
One could argue that RDBMS have been so successful because they give developers the freedom to model complex data, as well as complex relationships. Things have changed a lot since the 1970s, so different solutions emerged.
Key Value Stores like Redis are a blazing-fast and superb technology for simple use cases. Wide-column stores like Cassandra promise near linear scalability and fault tolerance. They are particularly strong in write intensive applications. Pure graph databases like Neo4J are facilitating modeling very complex relationships and Document stores like MongoDB accelerate development by providing a flexible data model and rich queries.
Nevertheless, there are 250+ products to chose from and that’s overcomplicating next generation architectures. Narrowly focused solutions solve only some of customers’ pain points. We’re often hearing the term polyglot persistence being used to describe the need to use more than one product to build an application. That’s imposing further restrictions, adding complexity and actually increasing the time to market.
Additionally, “SQL is the English of databases” and that’s not the real problem to solve. Forcing customers to learn a new dialect is not our way of thinking.
OrientDB marries the flexibility of Documents with the connectedness of Graphs and adds a familiar SQL interface and multiple APIs to access the same data. Users can simplify their architecture. Instead of combining different products, they can build a scalable and always consistent operational data store without complex ETL and processes to keep databases aligned.
I’ve been impressed to hear from customers that they like and share our vision. Data lakes are becoming common in the analytical and hadoop world. How about an operational datastore to rule them all?
Further reading: