
After a decade since the dawn of Cloud Computing, it is safe to say the Cloud is now ubiquitous. Cloud Infrastructures have been traditionally predicated on users being able to quickly spawn virtual machines at the press of a button, with the knowledge of physical placement and underlying hardware of those VMs being either partially or entirely hidden from the users.
On one hand, we are seeing this trend get even more prominent with the rise of containers, which introduce another layer of abstraction between applications and the physical infrastructure beneath them. On the other hand, Amazon Web Services recently released a new instance type, i3.metal, that provides direct access to server hardware, including VPC networking, EBS storage, and locally attached NVMe storage.
While this can be seen as opposing trends, this is not a zero-sum game. The needs of the application layer are often very different from the needs of the persistence layer, and therefore a wide selection of infrastructure services provides resources optimized for each layer’s needs. While the applications value flexibility and elasticity due to their stateless nature, the persistence layer tends to be more rigid and can benefit a lot from the extra performance that can come from having fewer layers between hardware and its software stack.
Before ScyllaDB came into play, inefficiencies in the software stack caused organizations to be forced to use many small virtual machines for NoSQL as a way to fight scalability issues. But as we demonstrated previously, ScyllaDB changes that equation by allowing deployments to not only scale out but also up by delivering linear scalability across any size of nodes. This makes the debut of bare metal offerings like i3.metal welcome news for ScyllaDB and its users.
In this article, we will explore the main differences between i3.16xlarge—the largest of the virtualized instances in the I3 family at AWS—and i3.metal. We will see that removing the virtualization layer brings gains in performance, allowing up to 31% faster write rates and read latencies up to 8x lower. That makes i3.metal and ScyllaDB the best combination for NoSQL deployments on AWS.
Readers should bear in mind that the even on the Xen-based hypervisors used for the current generation of I3, AWS does not overprovision VMs and statically partitions resources like memory, CPUs and I/O to specific processors. The virtualization overhead discussed in this article can grow larger on standard, unoptimized virtualization systems. Different private cloud configurations and different technologies like OpenStack or VMware may see a larger overhead. The KVM-based Nitro hypervisor by AWS is expected to decrease this overhead. Nitro can already be used today in the C5 and M5 instances.
The Specifications and Economics
In most modern operating systems and hypervisors, all resources can be flexibly shared among multiple processes and users. This allows for maximum efficiency in the utilization of resources. However, it is sometimes worth it to sacrifice efficiency to achieve better isolation and service level guarantees.
That is exactly what many cloud providers do: instead of just running the hypervisor code on every processor to make use of any idle cycles the tenants may have, it is sometimes better to dedicate resources exclusively for the hypervisor. AWS has been moving the code used to provide VPC networking, EBS storage, and local storage out of the hypervisor to dedicated hardware. And with that hypervisor code removed, those resources can be freed back to the tenants.
AWS offers an instance class optimized for I/O applications—the I3 family. So far, the largest instance type in the I3 class was i3.16xlarge. Since ScyllaDB is able to scale linearly to the size of those boxes, the i3.16xlarge has been our official recommendation since its debut.
Recently AWS announced the i3.metal instance type. It has the same hardware as i3.16xlarge, but the instance runs directly on the bare metal, without a hypervisor at all. As we can see in the comparison table below, four cores and 24 GiB of RAM are freed back to the tenant by removing the hypervisor. And since the price for those two instances is the same, the price per CPU, as well as the price per byte of memory in the i3.metal becomes the cheapest in the I3 class.

Table 1: Resource comparison between i3.16xlarge and i3.metal. It is clear from the outset that both instance types use the exact same hardware with the exception that i3.metal gives the resources used by the hypervisor back to the application. The hardware costs the same to the user, so i3.metal offers a better price point per resource.
Storage I/O
Both i3.16xlarge and i3.metal offer the exact same amount of attached storage, with the same underlying hardware. Since local NVMe storage and networking are implemented in hardware that largely bypasses the hypervisor, it’s easy to assume from that their performance will be the same, but in reality, the hypervisor will add overhead. Interrupts and inter-CPU communication may require action from the hypervisor which can impact the performance of the I/O stack.
We conducted some experiments using IOTune, a utility distributed with ScyllaDB that benchmarks storage arrays so that the ScyllaDB can find their real speed. The new version of IOTune, to be released with ScyllaDB 2.3, measures the aggregate storage’s read/write sequential throughput and read/write random IOPS, which makes it a great tool to comprehensively understand the behavior of the local NVMe storage in these two instances.
The results are summarized in Table 2. There is no visible difference in any of the sequential workloads, and in the random write workload. But when the aggregate storage needs to sustain very high IOPS, as is the case during random 4 kB reads, i3.metal is 9% faster than i3.16xlarge. This shows that AWS’s Xen based hypervisor used for virtualized I3 instances does not introduce much if any, overhead for moving large amounts of data quickly to and from local NVMe storage. But the highest storage I/O rates, which drive a very large number of interrupts, can experience some CPU utilization overhead due to virtualization.
| i3.16xlarge | i3.metal | Diff | |
| Sequential 1MB Writes | 6,231 MB/s | 6,228 MB/s | + 0% |
| Sequential 1MB Reads | 15,732 MB/s | 15,767 MB/s | + 0% |
| Random 4kB Writes | 1.45 M IOPS | 1.44 M IOPS | + 0% |
| Random 4kB Reads | 2.82 M IOPS | 3.08 M IOPS | + 9% |
Table 2: Storage I/O performance difference between i3.16xlarge and i3.metal. i3.metal can deliver up to 9% more performance in random reads, reaching 3 million IOPS.
The Network
During its setup phase, ScyllaDB analyzes the number of network queues available in the machine as well as the number of CPUs. If there are not enough queues to feed every CPU, ScyllaDB will isolate some of the CPUs to handle interrupt requests exclusively, leaving all others free of this processing.
Both i3.16xlarge and i3.metal use the same Elastic Network Adapter interface and have the same number of transmit and receive queues—not enough to distribute interrupts to all CPUs. During a network-heavy benchmark (to be discussed in the next section) we notice that the CPU utilization in the interrupt processing CPUs is much higher on i3.16xlarge. In fact, in one of them, there is no idle time at all.
Running perf in both instances can be illuminating, as it will tell us what exactly are those CPUs doing. Below we present the highest CPU consumers, found by executing perf top -C <irq_CPU> -F 99.
As we can see, i3.16xlarge processing is dominated by xen_hypercal_xxx functions. Those functions indicate communication between the operating system running in the instance and the Xen hypervisor due to software virtualized interrupt delivery for both I/O and inter-processor signaling used to forward the processing of a network packet from one CPU to another. Those are totally absent on i3.metal.
Putting It All Together: i3.Metal in Practice
We saw in the previous sections that the i3.metal instance type can benefit from more efficient I/O and more resources at the same price point. But how does that translate into real-world applications?
We ran simple benchmarks with ScyllaDB against two 3-node clusters. The first one, shown in green in the graphs below, uses three i3.16xlarge nodes. The second cluster, shown in yellow in the graphs below, uses three i3.metal nodes. Both clusters run the same AMI (us-east-1: ami-0ba7c874), running ScyllaDB 2.2rc0 and Linux 4.14. In all benchmarks below, nine c4.8xlarge instances connect to the cluster to act as load generators.
In the first benchmark, we insert random records at full speed with a uniform distribution for 40 minutes. Each record is a key-value pair and the values have 512 bytes each. We expect this workload to be CPU-bound and, since i3.metal has 12% more CPU cores available, we should see at least 12% more throughput due to ScyllaDB’s linear scaling up on a larger system. Any gains above that are a result of the processing itself being more efficient.
Figure 1 shows the results of the first benchmark. The i3.metal cluster achieves a peak of requests 35% higher than the i3.16xlarge cluster, and sustain an average write rate 31% higher than the i3.16xlarge cluster. Both those figures are higher than the 12% figure the amount of CPUs alone would predict, showing that the advantage of i3.metal stems fundamentally from more efficient resource usage.
Figure 2 shows the average CPU utilization in the two CPUs that ScyllaDB reserves for interrupt processing. While the i3.16xlarge cluster has those CPUs very close to their bottleneck, hitting 100% utilization at many times, the i3.metal cluster is comfortably below the 20% threshold for most of the benchmark’s execution.
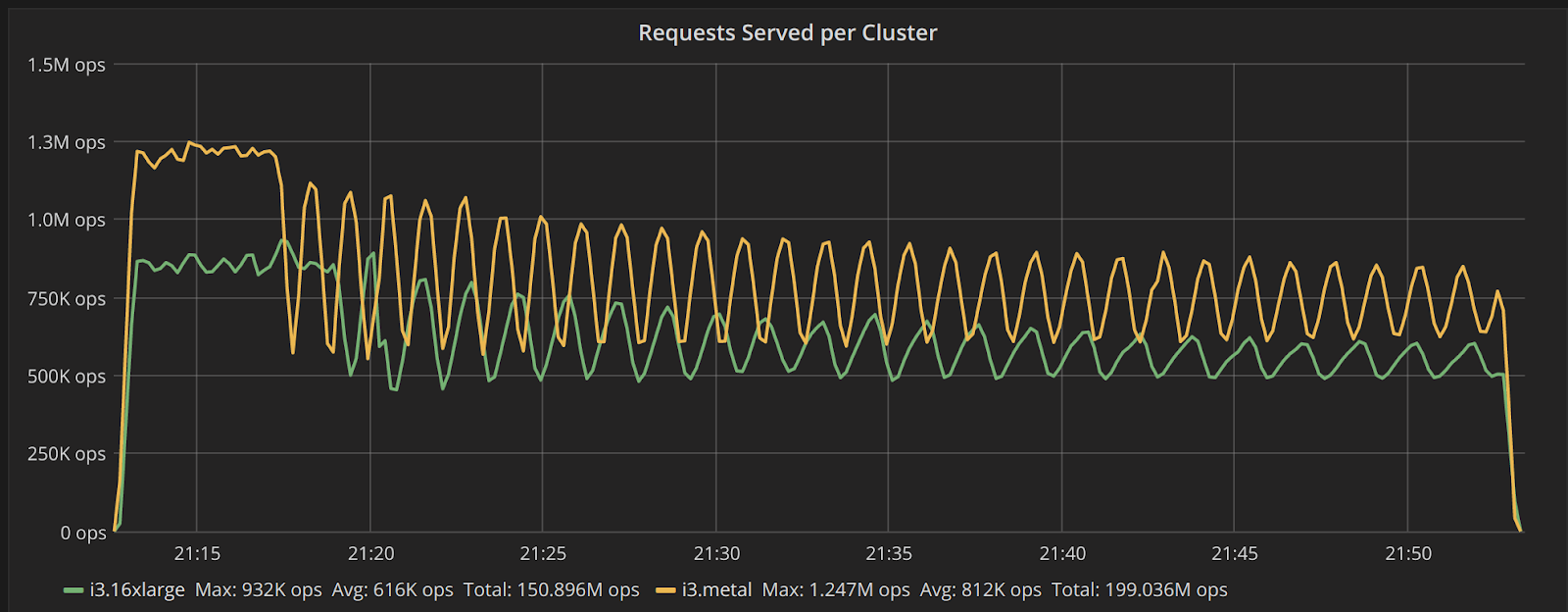
Figure 1: Write throughput for 512 byte values over time. The i3.16xlarge (green) cluster achieves a peak of 923,000 writes/s and sustains an average of 616,000 writes/s. The i3.metal (yellow) cluster achieves a peak of 1,247,000 writes/s—35% higher than i3.16xlarge, and sustains an average of 812,000 writes/s— 31% higher than the i3.16xlarge cluster.
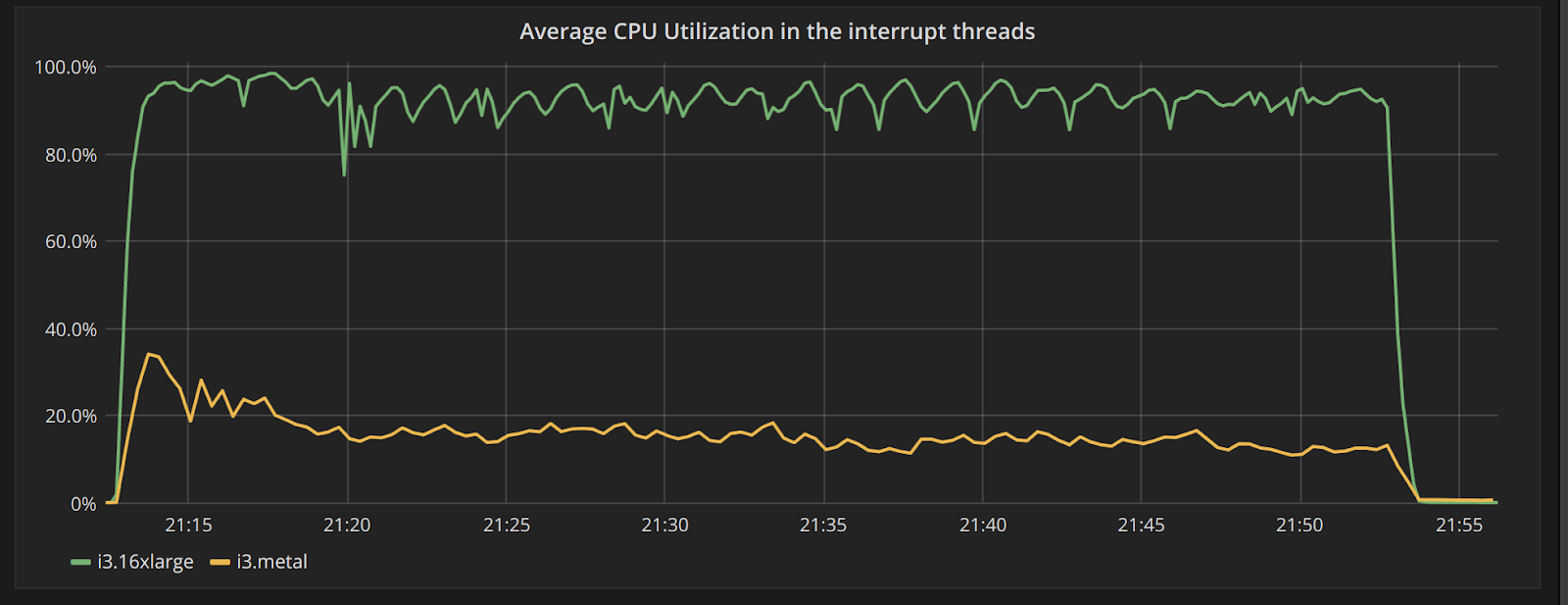
Figure 2: Average CPU utilization in the two CPUs isolated to handle network interrupts. The i3.metal cluster rarely crosses the 20% threshold while the i3.16xlarge cluster is seen close to saturation.
We saw that the i3.metal cluster is the clear winner for the write workloads. But what about reads? For reads, we are more interested in the latency metrics. To properly measure latencies, we will use a fixed throughput determined by the client—250,000 reads/s from a single replica. The database is populated with 4,500,000,000 key-value records with 1,024-byte values and we then read from those with a uniform distribution from the same nine c4.8xlarge clients with 100 threads each. With that distribution, we have 95% cache misses in both cases, making sure that the data is served from the local NVMe storage.
Before looking at the read request latency result, let’s first take a look at the latency of the I/O requests coming back from the NVMe storage itself. Figure 3 plots the maximum read latency seen in all NVMe SSDs for all three nodes in each of the clusters. We can see that each individual read request is completed in i3.metal under 100 microseconds—about half the latency compared to the read requests of the i3.16xlarge nodes. The performance over time is also a lot more consistent. This is despite the local NVMe storage being absolutely the same, showcasing again the gains to be had by removing the hypervisor and using i3.metal.
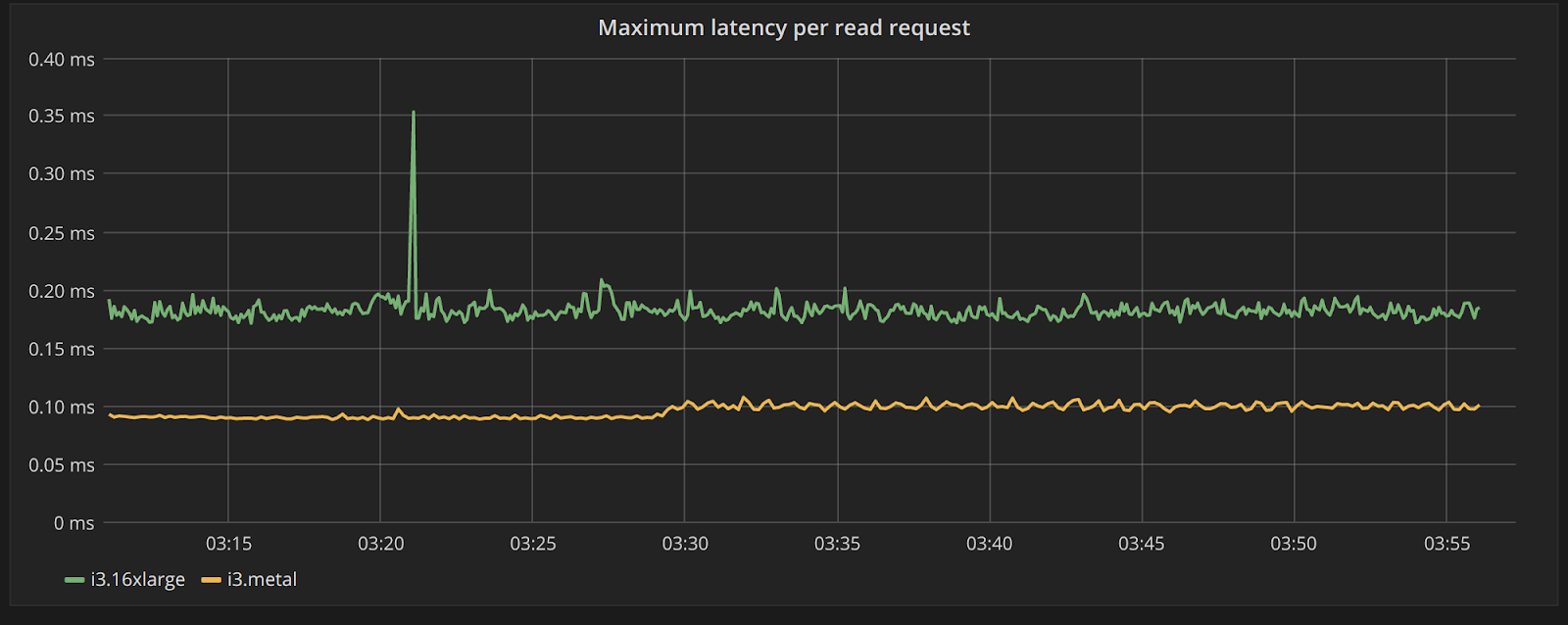
Figure 3: Maximum latency of read requests across all NVMe SSDs in all nodes in each cluster over time. The i3.metal cluster (in yellow) has half the latency of the i3.16xlarge cluster (green)
We saw above that all three core components of this workload—CPUs, storage, and network are faster and more efficient for i3.metal. So what is the end result? Table 3 shows the results seen at the end of the execution, in one of the client loaders. Latencies in all percentiles are better for the i3.metal cluster—with the average latency being below a millisecond.
The performance is also a lot more consistent. This can be seen in Table 3 from the fact that the difference between the two clusters grows in 99.9th percentile. But Figure 6 gives us an even better idea, by plotting the server-side latency across the cluster for the average and 99th percentile. We can see that not only read request latencies are much lower for the i3.metal cluster, they are also more consistent over time.
| average latency | 95th latency | 99th latency | 99.9th latency | |
| i3.16xlarge | 3.7ms | 6.0 ms | 9.8ms | 37.3ms |
| i3.metal | 0.9 ms | 1.1 ms | 2.4ms | 4.6ms |
| better by: | 4x | 5x | 4x | 8x |
Table 3: latencies seen from one of the clients connected to each cluster. The i3.metal cluster provides around 4x better results up to the 99th percentile. The 99.9th percentile is 8x better.
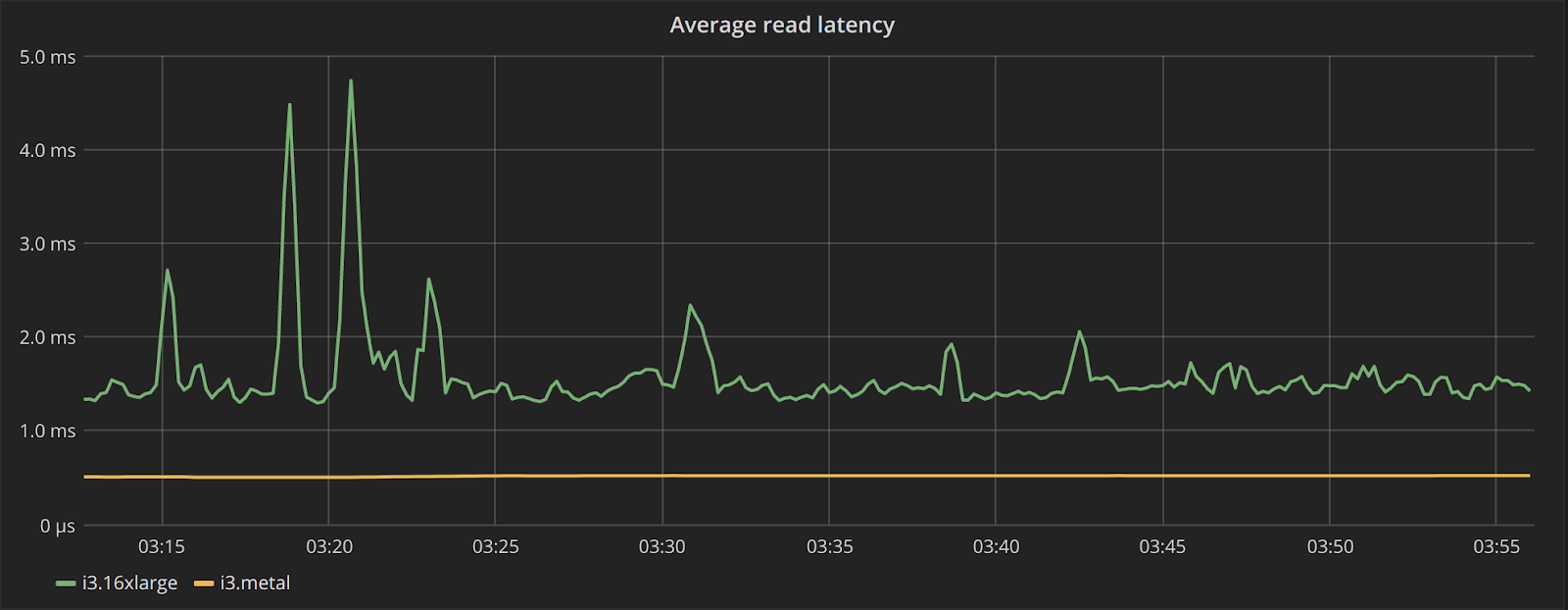
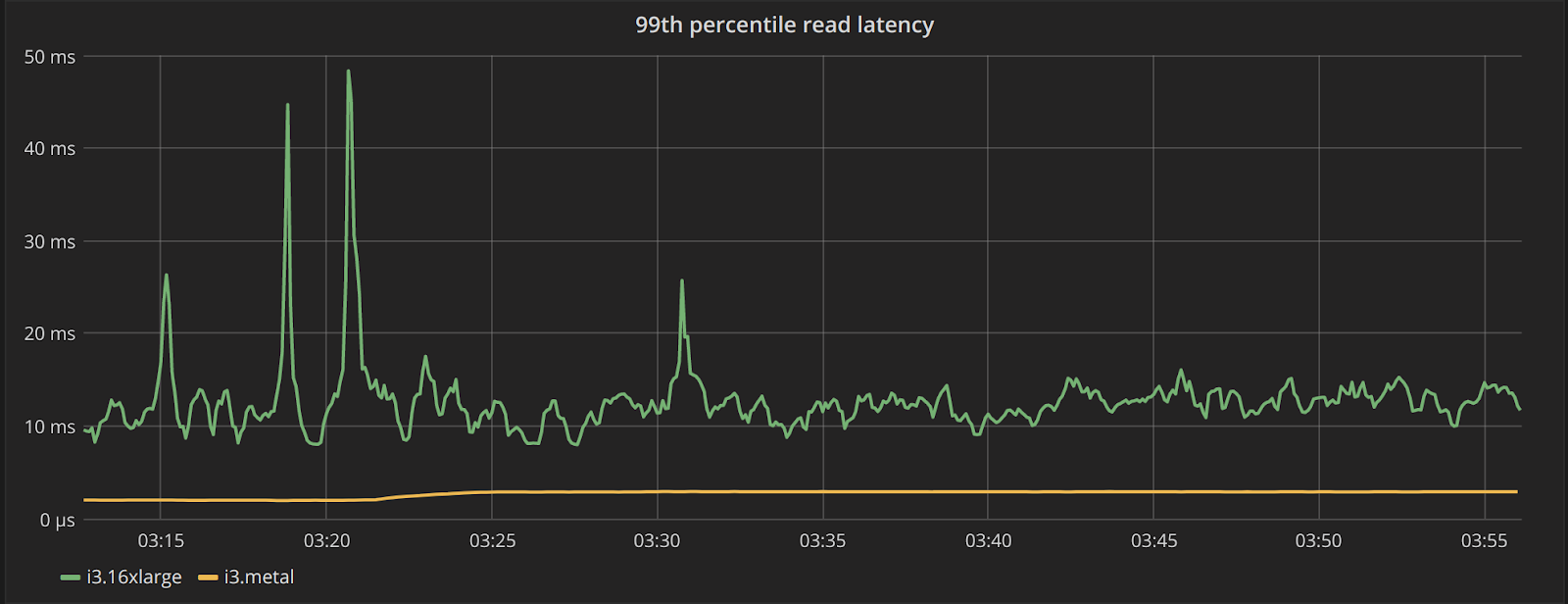
Figure 6: Top: average server-side read latency for the i3.16xlarge (green), and the i3.metal (yellow) cluster. Bottom: the 99th latency for those two same clusters. The latency seen in the i3.metal clusters is consistently lower and more predictable than the i3.16xlarge cluster.
Status of i3.metal Support
ScyllaDB fully supports i3.metal at this moment, for users who are using their own operating system AMIs.
In general, most current AMIs work with i3.metal out of the box, but some AMIs need modifications because they assume the EBS boot volume will be exposed as a paravirtualized Xen block device. But, like C5 and M5 instances, i3.metal instances provide access to EBS via NVMe devices. The CentOS base image used by the official ScyllaDB AMI to date was one such image. Our scripts used to automatically create the RAID arrays also break when they don’t find the boot volume exposed as EBS, which was already fixed. ScyllaDB official AMIs will support fully i3.metal starting with ScyllaDB 2.3.
Conclusion
AWS has recently made available a new instance type, i3.metal, that provides direct access to the bare metal without paying the price of the virtualization layer. Since ScyllaDB can scale up linearly as the boxes grow larger it is perfectly capable of using the extra resources made available for the users of i3.metal.
We showed in this article that despite having 12% more CPUs, i3.metal can sustain a 31% higher write throughput and up to 8x lower read latencies than i3.16xlarge, confirming our expectation that removing the hypervisor from the picture can also improve the efficiency of the resources.
With its increased efficiency, i3.metal offers the best hardware on AWS for I/O intensive applications. Together with ScyllaDB, it offers unmatched performance for Real-time Big Data workloads.
Next Steps



