
RC1 ArangoDB 3.4 – What’s new?
For ArangoDB 3.4 we already added 100,000 lines of code, happily deleted 50,000 lines and changed over 13,000 files until today. We merged countless PRs, invested months of problem solving, hacking, testing, hacking and testing again and are super excited to share the feature complete RC1 of ArangoDB 3.4 with you today.
Download the technical preview package for your OS: RC1 3.4 Community and RC1 3.4 Enterprise.
The team implemented over 40 new features, improvements and optimizations. In this short post, we will highlight just a few of them. You can find a full list in the release notes and follow the changes in the changelog.
This release candidate is the first release with a cluster-ready ArangoSearch integration, the long awaited GeoJSON support and Google’s S2 Geo Index, as well as pretty neat features like the Query Profiler and StreamingCursors. We also integrated many optimizations and improvements for RocksDB which will, from now on, be the default storage engine for ArangoDB (details below).
As you all know, a Release Candidate is not meant to be used in production!
Before we dive in
With ArangoSearch alone, we married two complex code bases – ArangoSearch based on the IResearch Library alone are +100,000 lines of C++. The team wrote thousands of lines of test code while our Q&A team is testing the new releases and all features from head to toe. However, we will need your help to make ArangoDB 3.4 ready for GA. Put us to the test and take the Release Candidate for a spin. Any feedback to issues is highly appreciated! “Great stuff, guys” is also welcome 🙂
Please let us know your thoughts via hackers@arangodb.com or issues via Github https://github.com/arangodb/arangodb/issues “ArangoDB version = 3.4 RC1”
ArangoSearch
ArangoSearch transforms ArangoDB from a data retrieval to an information retrieval solution. The new engine combines boolean retrieval capabilities with generalized ranking components which means that searching is based on a precise vector space model.
As a user you can link multiple collections and attributes to a view of type ‘arangosearch’. Similar to the concept of views in SQL, ArangoSearch references data stored in already existing collections but, in addition, allows for special indexing.
Analyzers and ranking algorithms (BM25, TFIDF) enable the vector-based similarity matching, which is more precise compared to boolean operations. This RC release and also ArangoDB 3.4 will provide special language analyzers including English, German, Spanish, Chinese, Swedish, Dutch and many more.
Of course, you can combine search with any other data model and access patterns.
Users can now perform:
- Relevance-based matching
- Phrase and Prefix matching
- Search with complex boolean expressions
- Query time relevance tuning
- Combine complex traversals, geo-queries, and other access patterns with information retrieval techniques
The RC1 implementation of ArangoSearch is now also cluster-ready.
ArangoSearch Architecture – Cluster Setup
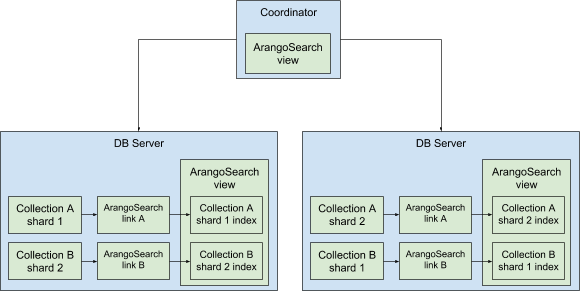
For those who want to take a technical deep-dive into the architecture of ArangoSearch, please find the details about ArangoSearch here or dive right in with the ArangoSearch Tutorial.
GeoJSON Support and Google S2 Index
Finally, the new geo features are complete and ready for action.  A few geo queries have been supported in ArangoDB for many years already, but with ArangoDB 3.4 we provide much more. With the upcoming release, ArangoDB will fully support GeoJSON with all geo primitives, including multi-polygons or multi-line strings.
A few geo queries have been supported in ArangoDB for many years already, but with ArangoDB 3.4 we provide much more. With the upcoming release, ArangoDB will fully support GeoJSON with all geo primitives, including multi-polygons or multi-line strings.
The team developing the new geo functionalities invested a lot of work to increase query and filtering functionalities but also optimized performance. Therefore, we integrated Googles S2 Geo Index library which also works perfectly with our RocksDB storage engine.
To put the icing on the cake, you can directly visualize your results in OpenStreetMap integrated in the Query Editor of ArangoDBs WebUI.
Learn about GeoJSON support with the new hands-on GeoJSON tutorial.
Query Profiler
Great performance is everybody’s darling. Complex queries can become very unclear when trying to optimize. ArangoDB 3.4 makes it much easier to profile your queries and get insights into how much time was spent where.
By using `db._profileQuery(..)` in arangosh or by hitting the “Profile” button within the query tab of the WebUI, you can now execute additional instrumentation code that provides details about:
- Call: The number of times this query stage was executed
- Items: The number of temporary result rows at this stage
- Runtime: The total time spent in this stage
Below the execution plan, there are additional sections for the overall runtime statistics and the query profile.
The query profile for the AQL
FOR doc IN collection
FILTER doc.value < 10
RETURN docwill look like the arangosh output below.
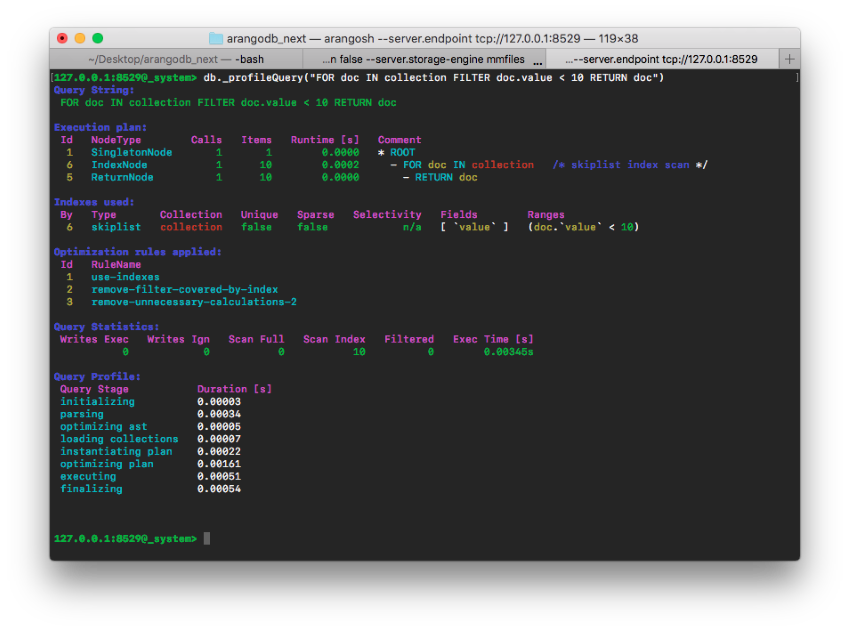
Learn about Query Optimization with the new Query Profiler Tutorial.
Streaming Cursors
Sometimes the overall query performance is not the first priority, but rather how fast a user gets first results to be displayed or used elsewhere. Based on community feedback, we integrated streaming cursors which allow users to get first results as they become available.
Assume a query result sends back up to 1000 results for your query. Without streaming, the results will be sent to the client only if the whole query has been processed entirely. By defining ‘stream = true’ for your cursor, the client receives the first results as they become available on the server. Read more about Streaming AQL Cursors.
Please note our caveats and recommendations when using streaming cursors.
RockDB as Default Storage Engine
Previous versions of ArangoDB had MMfiles as their default storage engine. With ArangoDB 3.4, this will change to RocksDB. If a storage engine is not defined explicitly or the setting is set to ‘auto’ then RocksDB will be used as the storage engine. If you just update an existing installation, then the previously defined engine will be used.
After this quick introduction, let’s see what’s new and improved:
- Optimized Binary Storage Format: The new format is optimized for RocksDB and can be utilized for fresh installations. A key benefit of the new format is greatly improved insertion performance.
- Optional Caching: Users can now specify a new per-collection property ‘cacheEnabled’ to define documents and primary index values to be cached in-memory. This leads to significant performance improvements for multiple cases; especially for point-lookups
- Reduced Replication Catch-Up time: A lot was optimized for a better replication experience for auto-failover, cluster and DC2DC settings.
- Exclusive Collection Access Option: RocksDB now allows users to define collections with exclusive write access. This can simplify application development.
- Enhanced WAL sync control: Users can now configure how frequently the WAL syncs to disk/SSD.
We are in this together
We could go on for quite a while to list everything that is new in the upcoming v3.4. Find an almost complete list in our Release Notes for 3.4. We improved so many things under the hood, especially for cluster performance and stability, that we just can’t list everything individually.
Hopefully, there are also some useful new features for your projects and needs.
It would be very helpful for us to get your feedback about RC1. Test it with your data, queries, setups and let us know what you think via hackers@arangodb.com or if you found any issues via Github using “ArangoDB version = 3.4 RC1”
Let’s ship something useful together!
Get the latest tutorials, blog posts and news: