Building an Evernote to SQLite exporter
16th October 2020
I’ve been using Evernote for over a decade, and I’ve long wanted to export my data from it so I can do interesting things with it.
Ideally I’d use their API for that, so I could continually export new notes via a cron. Unfortunately the API is implemented using Thrift (the only public API I’ve seen to use that) and my attempts to speak to it from Python have so far failed to get anywhere.
Last weekend I decided to try using their “Export notes” feature instead, and its ENEX XML format.
ENEX—the Evernote XML export format
Select a note—or multiple notes—in the Evernote macOS desktop app, use the File -> Export Notes menu item and Evernote will create a Notes.enex exported XML file.
These files can get BIG, because any images attached to your notes will be embedded as base64 encoded binary data within the XML. My export is 2.8GB!
When faced with unknown XML like this it’s useful to get a high level overview of what tags are present. in 2009 I wrote a Python script for this—as part of this project I updated it for Python 3 and pushed a release to PyPI.
Here’s a subset of the output when run against my Notes.enex file (full output is here).
{
"note": {
"attr_counts": {},
"child_counts": {
"content": 2126,
"created": 2126,
"note-attributes": 2126,
"resource": 2605,
"tag": 45,
"title": 2126,
"updated": 2126
},
"count": 2126,
"parent_counts": {
"en-export": 2126
}
},
"note-attributes": {
"attr_counts": {},
"child_counts": {
"altitude": 1466,
"application-data": 449,
"author": 998,
"classifications": 51,
"content-class": 387,
"latitude": 1480,
"longitude": 1480,
"reminder-done-time": 2,
"reminder-order": 2126,
"reminder-time": 1,
"source": 1664,
"source-application": 423,
"source-url": 85,
"subject-date": 10
},
"count": 2126,
"parent_counts": {
"note": 2126
}
}
}This shows me that every note is represented as a <note> element, and crucial metadata lives in children of a <note-attributes> child element.
(I thought I’d need to tweak the script for performance since it works by loading the entire file into memory, but my laptop has 32GB of RAM so it didn’t even blink.)
ENEX limitations
I ran into some significant limitations while working with my ENEX export.
- Notebooks are not represented in the file at all—you just get the notes. So I can’t tell which recipes were in my “cooking” notebook. It’s possible to work around this by manually exporting the notes from each notebook one at a time and storing them in separate export files. I didn’t bother.
- Some of the data in the file—the note content itself for example—consists of further blocks of XML embedded in CDATA. This means you have to run a nested XML parser for every note you process.
- The notes XML
<en-note>format is mostly XHTML, but includes custom<en-media hash="...">tags where inline images should be displayed - Those inline images are CDATA encoded base64 strings. They don’t include a hash, but I figured out that decoding the base64 string and then running it through MD5 generates the hash that is used in the corresponding
<en-media>tag. - Notes in the export don’t have any form of unique ID!
That last limitation—the lack of unique IDs—is a huge pain. It means that any export is by necessity a one-time operation—if you edit a note and attempt a re-export you will get a brand new record that can’t be automatically used to update the previous one.
This is particularly frustrating because I know that Evernote assigns a GUID to each note—they just don’t include them in the export file.
Writing an exporter
My Dogsheep family of tools aims to liberate personal data from all kinds of different sources and convert it into SQLite, which means I can explore, query and visualize it using Datasette.
dogsheep/evernote-to-sqlite is my latest entry in that series.
I based it on healthkit-to-sqlite because that, too, has to deal with a multiple GB XML file. Both tools use the Python standard library’s XMLPullParser, which makes XML elements available as a stream without needing to load the entire file into memory at once.
The conversion code is here. It ended up being relatively straight-forward, using ElementTree to extract data from the XML and sqlite-utils to write it to a database.
It implements a progress bar by tracking the number of bytes that have been read from the underlying file XML.
One optimization: originally I created a single resources table with the resource metadata and a BLOB column containing the binary image contents.
This table was huge—over a GB—and had very poor performance for operations such as querying and faceting across unindexed columns—because any table scan had to work through MBs of binary data.
My personal Evernote notebook has around 2,000 resources. 2,000 rows of metadata should usually be very fast to query.
So... I split the binary data out into a two column resources_data table—md5 primary key and a BLOB for data. This massively sped up queries against that resources table.
And it works! Running the following command produces a SQLite database file containing all of my notes, note metadata and embedded images:
evernote-to-sqlite enex evernote.db MyNotes.enex
Serving up formatted notes
Figuring out the best way to serve up the note content in Datasette is still a work in progress—but I’ve hacked together a delightfully terrible way of doing this using a one-off plugin.
Datasette plugins are usually packaged and installed via PyPI, but there’s an alternative option for plugins that don’t warrant distribution: create a plugins/ directory, drop in one or more Python files and start Datasette pointing --plugins-dir at that directory.
This is great for hacking on terrible ideas. Here’s the evernote.py plugin I wrote in full:
from datasette import hookimpl import jinja2 START = "<en-note" END = "</en-note>" TEMPLATE = """ <div style="max-width: 500px; white-space: normal; overflow-wrap: break-word;">{}</div> """.strip() EN_MEDIA_SCRIPT = """ Array.from(document.querySelectorAll('en-media')).forEach(el => { let hash = el.getAttribute('hash'); let type = el.getAttribute('type'); let path = `/evernote/resources_data/${hash}.json?_shape=array`; fetch(path).then(r => r.json()).then(rows => { let b64 = rows[0].data.encoded; let data = `data:${type};base64,${b64}`; el.innerHTML = `<img style="max-width: 300px" src="${data}">`; }); }); """ @hookimpl def render_cell(value, table): if not table: # Don't render content from arbitrary SQL queries, could be XSS hole return if not value or not isinstance(value, str): return value = value.strip() if value.startswith(START) and value.endswith(END): trimmed = value[len(START) : -len(END)] trimmed = trimmed.split(">", 1)[1] # Replace those horrible double newlines trimmed = trimmed.replace("<div><br /></div>", "<br>") return jinja2.Markup(TEMPLATE.format(trimmed)) @hookimpl def extra_body_script(): return EN_MEDIA_SCRIPT
This uses two Datasette plugin hooks.
render_cell() is called every time Datasette’s interface renders the value of a column. Here I’m looking for the <en-note> and </en-note> tags and, if they are present, stripping them off and marking their inner content as safe to display using jinja2.Markup() (without this they would be automatically HTML esacped).
extra_body_script() can be used to inject additional JavaScript at the bottom of the page. I’m injecting some particularly devious JavaScript which scans the page for Evernote’s <en-media> tags and, if it finds any, runs a fetch() to get the base64-encoded data from Datasette and then injects that into the page as a 300px wide image element using a data: URI.
Like I said, this is a pretty terrifying hack! But it works just fine, and my notes are now visible inside my personal Datasette instance:
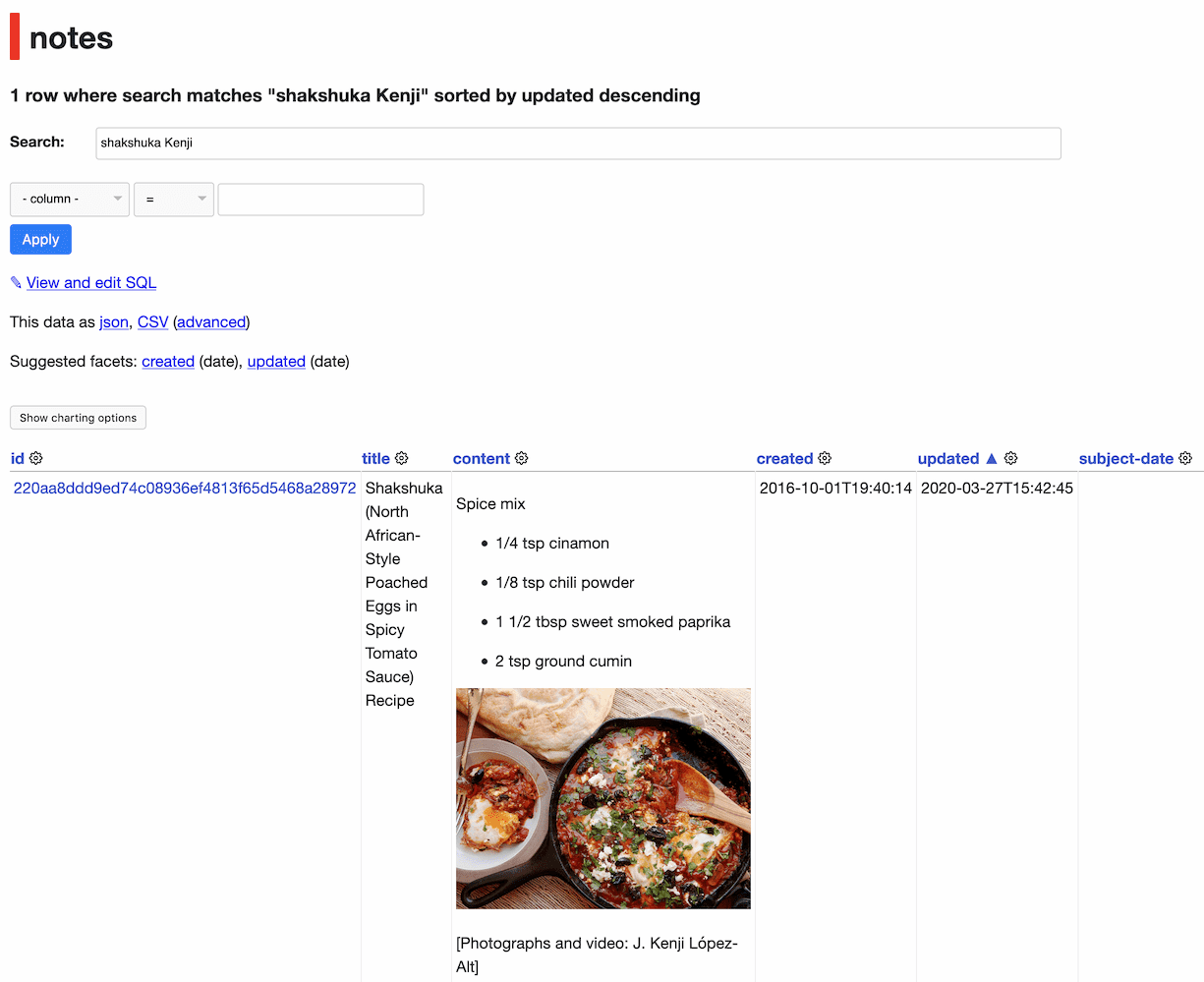
Bonus feature: search by OCR
An interesting feature of Evernote is that it runs cloud-based OCR against images in your notes, enabling you to search across the text contained within them.
It turns out the output of this OCR process is included in the export XML. It looks like this:
<recoIndex
docType="unknown"
objType="image" objID="76dd28b07797cc9f3f129c4871c5293c"
engineVersion="7.0.24.1"
recoType="service"
lang="en"
objWidth="670"
objHeight="128">
<item x="26" y="52" w="81" h="29">
<t w="76">This</t>
</item>
<item x="134" y="52" w="35" h="29">
<t w="79">is</t>
</item>
<item x="196" y="60" w="37" h="21">
<t w="73">so</t>
</item>
<item x="300" y="60" w="57" h="21">
<t w="71">can</t>
</item>
<item x="382" y="54" w="79" h="27">
<t w="77">test</t>
</item>
<item x="486" y="52" w="59" h="29">
<t w="82">the</t>
</item>
<item x="570" y="54" w="59" h="25">
<t w="74">OCR</t>
<t w="33">DeR</t>
<t w="15">OCR!</t>
<t w="14">OCR]</t>
</item>
</recoIndex>As far as I can tell an <item> gets multiple <t> elements only if the OCR wasn’t 100% sure.
evernote-to-sqlite creates a searchable ocr text field using values from that XML, so I can search my images in Datasette.
More recent articles
- AI for Data Journalism: demonstrating what we can do with this stuff right now - 17th April 2024
- Three major LLM releases in 24 hours (plus weeknotes) - 10th April 2024
- Building files-to-prompt entirely using Claude 3 Opus - 8th April 2024
- Running OCR against PDFs and images directly in your browser - 30th March 2024
- llm cmd undo last git commit - a new plugin for LLM - 26th March 2024
- Building and testing C extensions for SQLite with ChatGPT Code Interpreter - 23rd March 2024
- Claude and ChatGPT for ad-hoc sidequests - 22nd March 2024
- Weeknotes: the aftermath of NICAR - 16th March 2024
- The GPT-4 barrier has finally been broken - 8th March 2024
- Prompt injection and jailbreaking are not the same thing - 5th March 2024