#332 — November 27, 2020 |
Database Weekly |
|
|
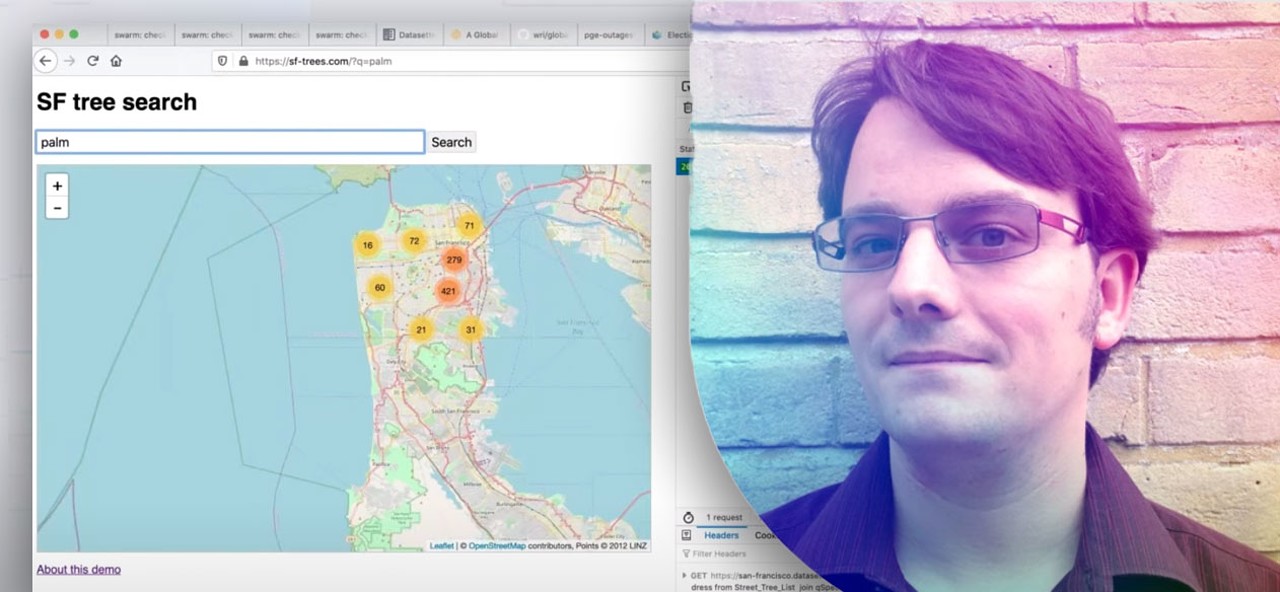
Personal Data Warehouses: Reclaiming Your Data — Simon, one of Django’s co-creators, is becoming increasingly well known for his work on SQLite-based data management tools like Datasette. In this talk (coupled with a written summary you can follow without watching the video) he covered the topic of ‘personal data warehouses’ and why you might want to build them for yourself. Fantastic! Simon Willison |
|
DynamoDB Gets a SQL-Compatible Query Language — Last year we featured Amazon’s announcement of PartiQL, a ‘one query language for all your data’, which aimed to take SQL into very non-relational places. Support for it has now arrived in DynamoDB which will open up some interesting use cases for sure.. Amazon Web Services |

Free Guide: How to Manage State in Kubernetes — Managing state in Kubernetes is a challenge. But many applications require it. This guide shows you a few different ways to manage state in k8s - with different kinds of tradeoffs. Cockroach Labs sponsor |
|
How Medium Counts Followers — An interesting look behind the scenes at Medium, the content paywall experts, at both a disruption in their analytics and the underlying data model of how they track followers to its many users and publications. An Vu (Medium Engineering) |
|
Using SQLite as a Document Database — Somehow, I keep forgetting about SQLite’s JSON functionality, but David notes that adding this to the recently added generated columns feature offers some neater ways to use SQLite as a document database. David Leadbeater |
|
Postgres: The 'Batteries Included' Database? — Frameworks like Django or Ruby on Rails can be called ‘batteries included’ systems because they include authentication, an ORM, tooling, and more out of the box. Postgres is like that in the database sphere, argues Craig – it has it all (or it can be added!) Craig Kerstiens |
|
⏰ Time-Series Data, Explained — Learn why time-series data is unique and how to use it in your projects, complete with 3 sample queries to get you up and running 👟 Timescale sponsor |
|
Reasons Why Tanel Põder |
|
5 Simple Examples to Understand Elasticsearch Aggregation — It’s easy to think of Elasticsearch as just being a full text search engine, but really it’s a full fledged document database complete with aggregate functions as demonstrated here. Anuj Verma |
|
Improving ElasticSearch Relevance with Data-Driven Query Optimization — How to use a labeled relevance dataset to improve your search relevance with hands-on examples using Elasticsearch. Josh Devins (Elastic) |
|
A Brief History of Enterprise Data Challenges — A brief attempt to summarize the key shifts in the data ecosystem from 2000 to now. Hassen Chaieb |
🔨 Code and Tools |
|
libmdbx: A Super Fast, Embedded, Key Value Database — An embeddable key-value ACID database without a WAL that claims to surpass even LMDB in terms of reliability, features and performance. Леонид Юрьев (Leonid Yuriev) |
|
Data Headaches Targeted with a Dose of .BIG — .BIG is a new data file format developed by Exponam to address issues around transferring and sharing large datasets (i.e. where 100 million row CSV files just won’t cut it). It has some similarities to Parquet but with huge compression advantages. Alex Woodie (Datanami) |
|
MonetDBe-Python: Embedded MonetDB with a Python Frontend and Fast Numpy/Pandas Support — MonetDB is an open source, high performance column oriented data store, and this brings it onto your machine in more of an SQLite style for doing local analysis. Just a MonetDB Solutions |
|
Setting Up GraphQL for an SQL Database in Python
|
💻 Job |
|
DevOps Engineer at X-Team (Remote) — Join the most energizing community for developers and work on projects for Riot Games, FOX, Sony, Coinbase, and more. X-Team |